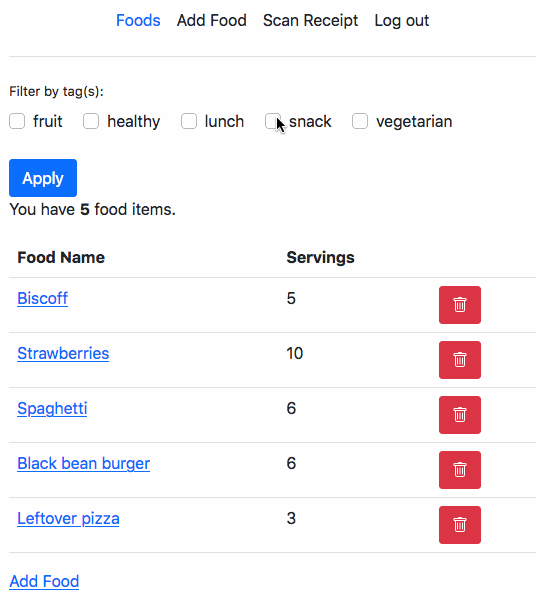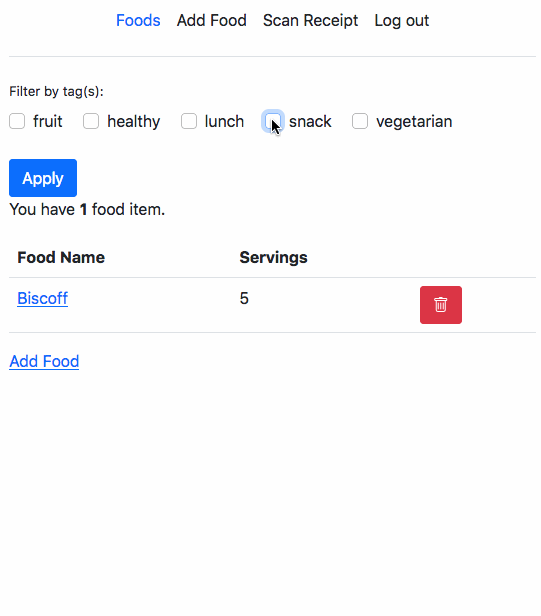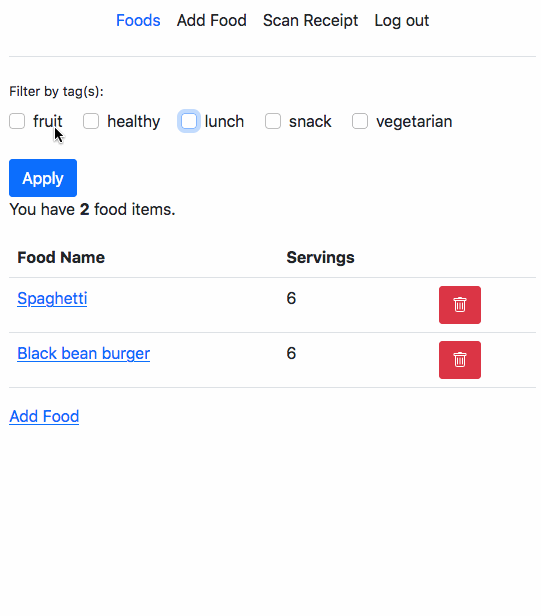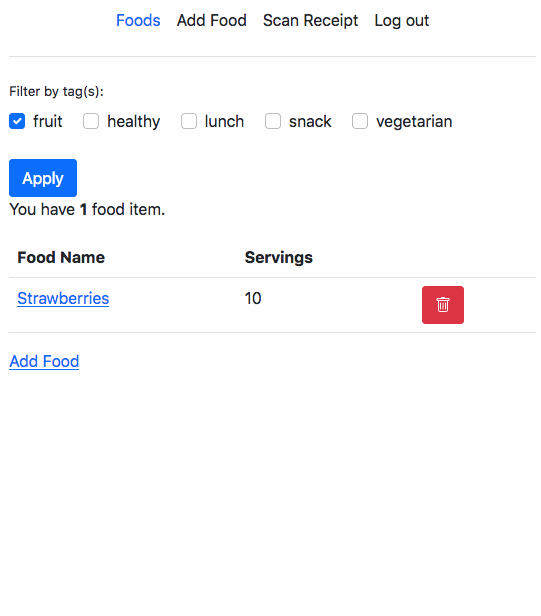
Recently I had some free time and decided to checkout a few questions from LeetCode.
Struggled and relearned a few insights during this experiment so writing them down for my future self.
The idea is to document the unfiltered process, revisit what worked and what did not to improve problem solving skills.
Here’s how it went down along with some relevant commentary.
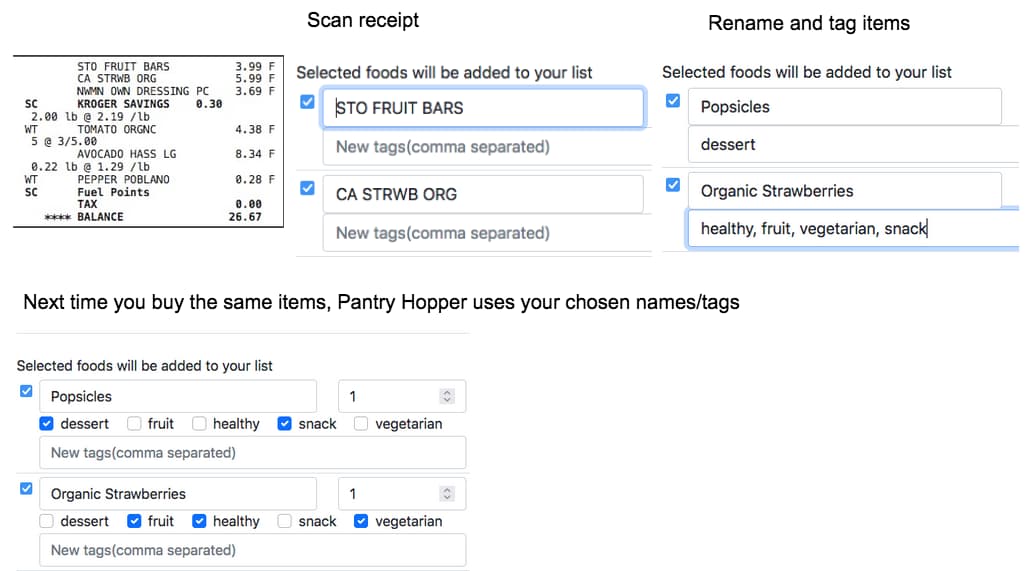
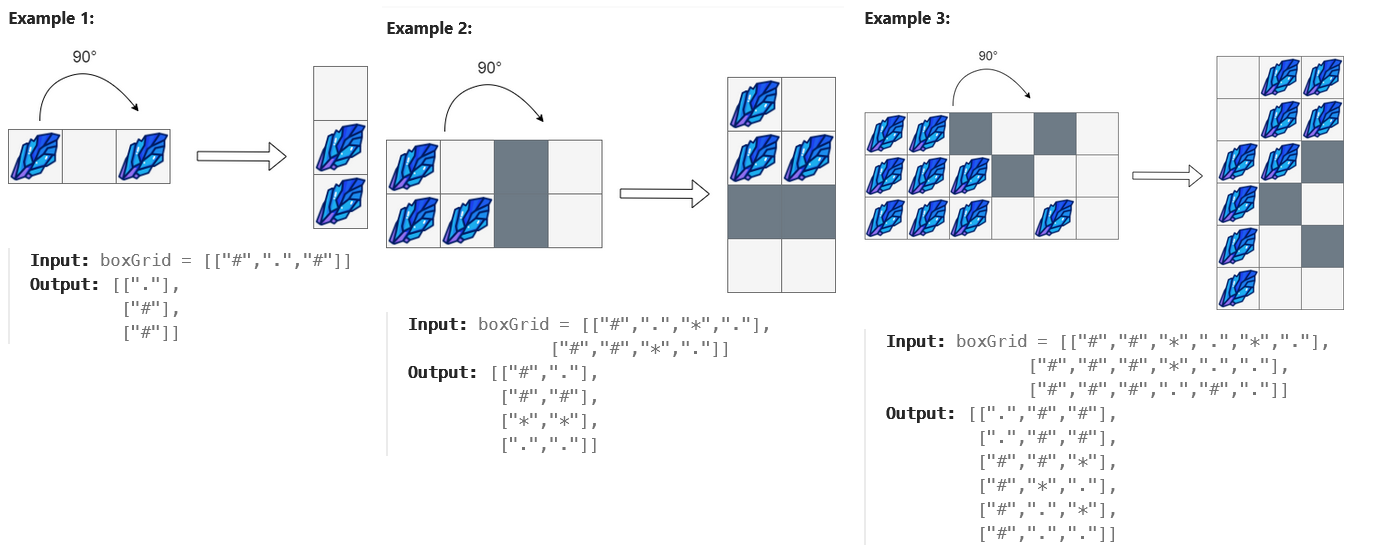
Picked a medium level problem about rotating a box that may contain stone(s), stationary object(s), obstacle(s) or empty space. The details:
1 | /* |
Chapter 1 - I can do it
Dove into LeetCode editor and started coding; assumed that I could figure things out along the way, did not get far. Then I remembered a wise man talking about syncing to paper. Not surprisingly, this is the strategy that Cracking the Code Interview book suggests. Great minds think alike eh?
Chapter 2 - Boxes and Lines
Started drawing the arrays to frame the problem. A few themes appeared. Need a rotated box (transformed array) and a way to transfer the items from the original box to the rotated box. Tried to do both, got quickly overwhelmed by edge cases.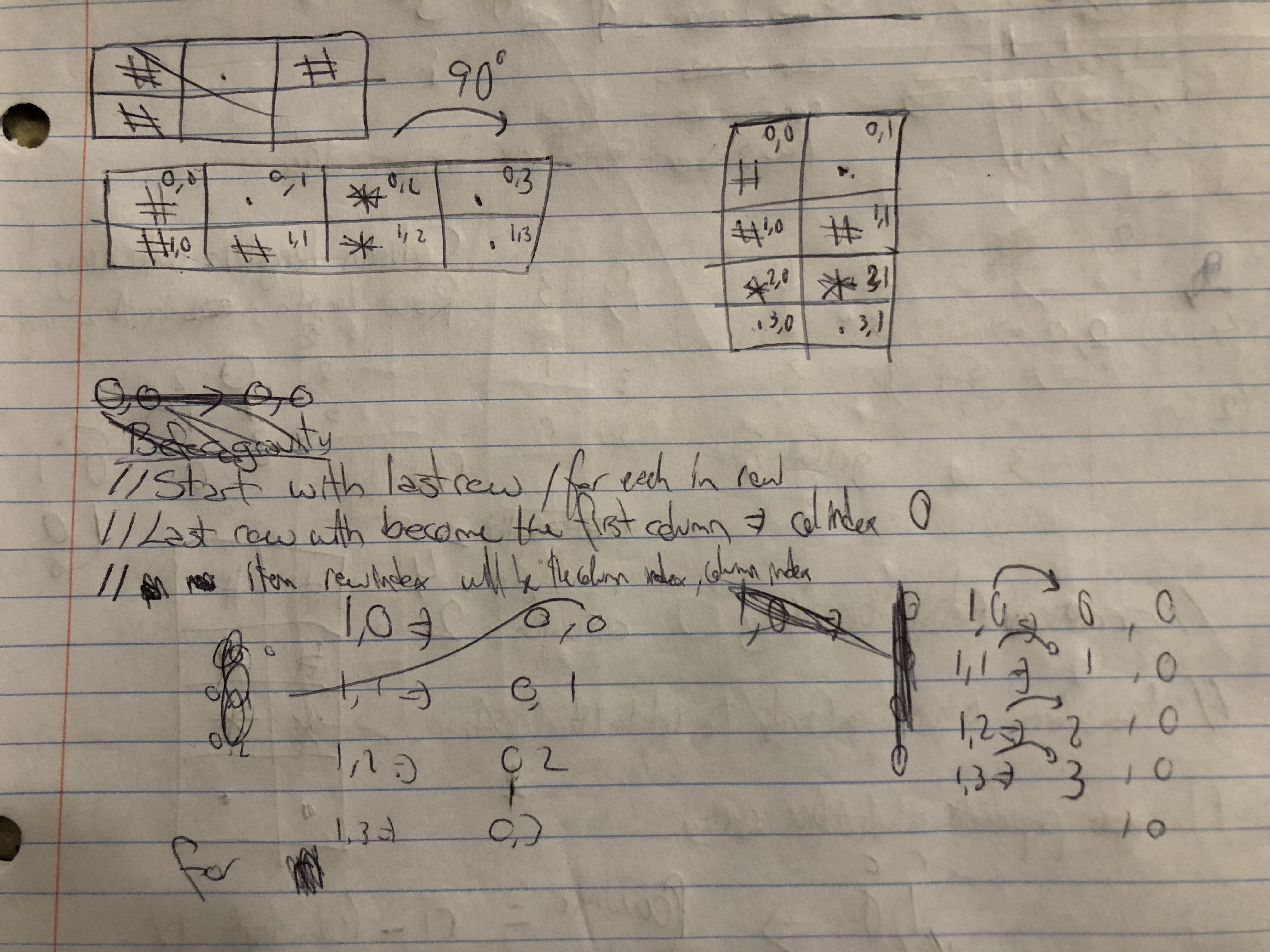
Chapter 3 - Break it down
Decided to break down the problem into smaller pieces.
- Create a rotated box
- Move items from the original box to the rotated box
- Apply gravity to move the stones above empty spaces
Chapter 4 - Progress!
Tackling the first problem using the drawings some patterns emerged.
- Last row in the original box becomes the first column in the rotated box
- Second to last row in the original box becomes the second column in the rotated box
…
Ignoring the contents of the original box (array) wrote a function to simply rotate the box (array) and tested with different row/column sizes.
1 | const createRotatedBox = (rowLength, columnLength, box) => { |
Chapter 5 - Moving Day
It’s time to move the items from the original box to the rotated box. I found it difficult to map the coordinates in the original box to the coordinates in the rotated box. My plan was to write a function that would say:
- the item in (0, 2) in the original box will go into (2, 2) in the rotated box
so I created another visual to help tease out the pattern(s)
This made it easier to see the source and target coordinates of each item at a glance. That led to the following simple (in hindsight) function to get the target coordinates from the source coordinates.
1 | const getRotatedBoxIndex = (rowIndex, columnIndex, rowLength) => |
Chapter 6 - Gravity
The last small problem to solve was applying gravity and swapping the location of the stones if there is/are space(s) below them.
My strategy was to iterate over the columns, look at the contents and swap items accordingly. Started writing down the conditions when gravity would apply
- if there is a stone in the column and
- if there is a empty space below the stone
- what if there is another empty space below that
- …
I reluctantly had to admit that recursion may be needed in this scenario i.e. for each column start from the top and swap each stone and the empty space below it.
It’s crucial to determine the exit conditions when dealing with recursive functions. A light bulb went off in my head while thinking about when the code should stop applying gravity (swapping items) to the column.
If the code iterated through all the items in the column AND did not swap anything,
then we’re done with that column
else applyGravity again (recurse)
Behold the applyGravity function that is tested separately from the rest of the code:
1 | const applyGravity= (items) => { |
Now we have a function that can take an array of items in a column and applyGravity to that column swapping items if necessary. Therefore, the remaining steps are:
- Get the columns (array of items in the column) from the rotated/populated box
- Call applyGravity passing the items in that column (swapping items if necessary)
- After calling applyGravity on each column, put the columns back together (rebuilding the rotated box)
Chapter 7 - AI all the things!
You have been waiting patiently to see when an LLM would come into play. Well, here it is.
Claude prompt:
1 | javascript function that returns an array of columns for a two dimensional array |
response:
1 | function extractColumns(array) { |
Claude prompt:
1 | now write a function to return a two dimensional array from a columns array |
response:
1 | /*I'll create a complementary function that converts an array of columns back into a two-dimensional array.*/ |
I know exactly what these two functions are doing but I’m too lazy to write it myself.
Chapter 8 - Will it work?
1 | var rotateTheBox = function(box) { |
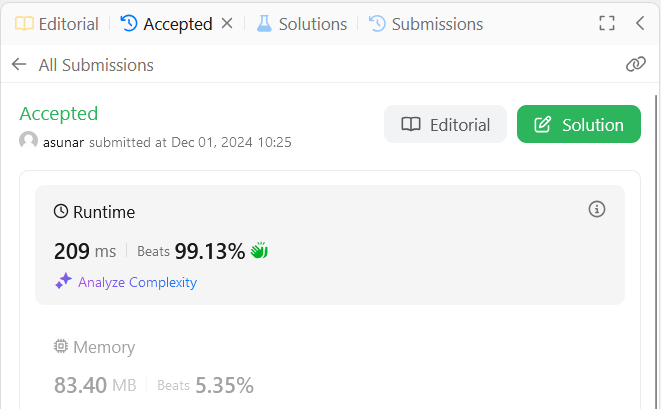
Not bad for the first iteration.
Afterword
I noticed that simply breaking down the problem enabled working on each one separately reducing the mental load. The functions in the solutions are easy to read (if I may say so myself) and self-contained. Despite mutating state I think the overall solution is comprised of pure functions.
A happy side-effect of this strategy is that in a bigger team we can write unit tests for each of these functions and have multiple developers work on them at the same time going forward.